저번 시간에 이어 이제 날짜별로 저장된 데이터를 예측해본다.
원래는 다음날의 종가를 알고 싶었지만, 여기서는 예측하여 그것을 그래프로 나타낸다.
Keras의 LSTM을 사용한다.
*Keras를 사용하기 위해 텐서플로우 패키지를 설치하려 했지만, 필자의 파이썬 버전이 3.8이라 텐서플로우가 설치되지 않는다. 텐서플로우는 3.7이하의 파이썬 버전이 필요해서 colab을 통해 진행한다.
데이터 확인
Colab 프로젝트에 먼저 이전시간에 저장한 주식 데이터를 로드하고 아래와 같이 필요한 패키지를 import한다.
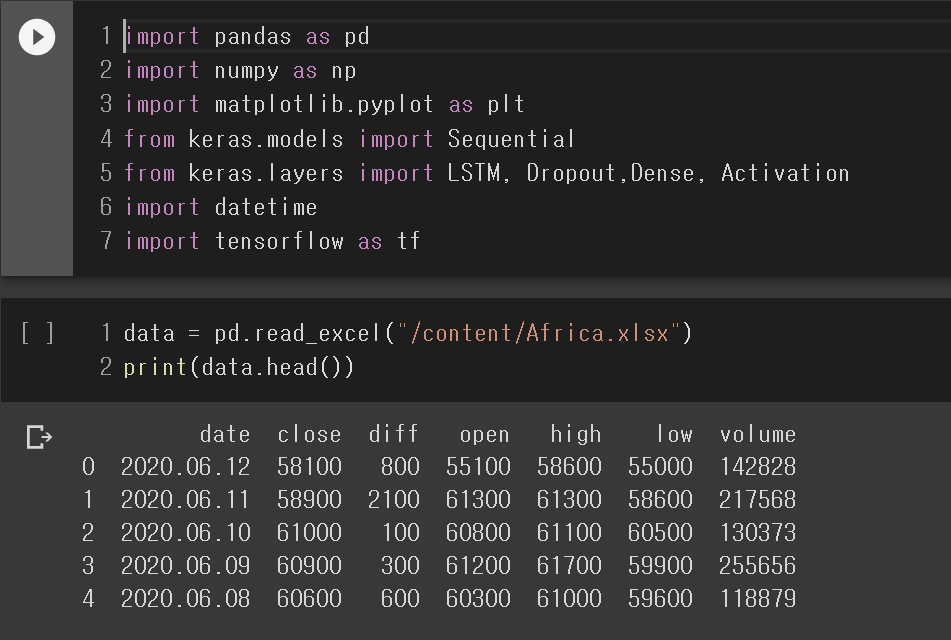
이전에 우리가 저장한 상위 데이터 5개를 확인할 수 있다. 최신 데이터까지 필요하다면 이전 글을 참고하여 최신 데이터까지 Pandas를 사용해 저장한다.
데이터 저장 및 예측 단위 설정

이제 최고가, 최저가, 중간 가격을 만들고 최근 데이터인 50일을 기준으로 잘라내어 해당 데이터로 다음 날의 가격을 예측하도록 한다. 자르는 기준은 마음대로 해도 무방하다.
데이터 정규화

모델을 잘 예측하기 위한 과정이며, 우리가 정한 50일인 50개의 데이터중 첫번째 값을 0으로 하고 나머지 값을 그 비율만큼 조정한다.
훈련 데이터, 테스트 데이터
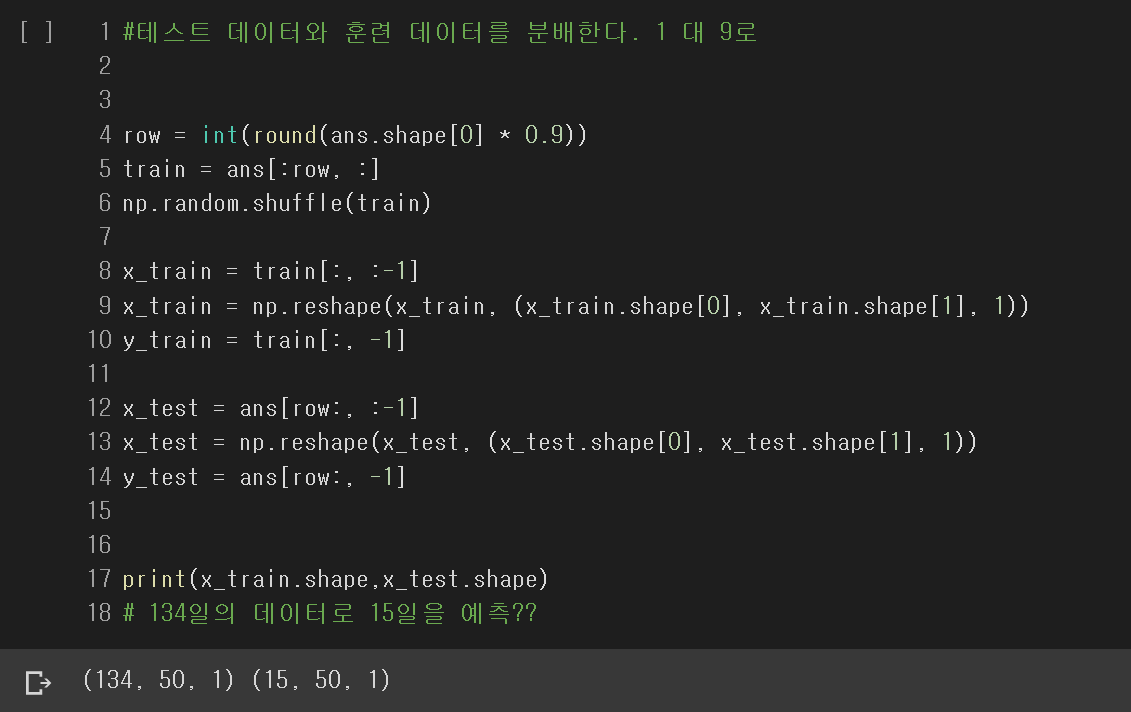
이제 훈련데이터와 테스트 데이터를 나눠준다. 7:3으로 해도 무방하며 여기서는 9:1로 데이터를 나눠준다.
출력을 보면 134일의 데이터로 학습하고 15일 데이터로 테스트를 진행할것임을 나타낸다.
모델

모델은 위오 같다. 단순한 모델이며 출력창에서 모델이 어떻게 되어있는지 확인할 수 있다. 2개의 LSTM이 있으며 첫번째 모델은 유닛수가 50, 두번째는 64개 있음을 확인할 수 있다. 손실함수와 옵티마이저는 위와 같이 사용했으며 다른 함수를 사용해도 무방하다.
그래프 그리기

matplotlib을 이용하여 그림을 그리면 아래와 같다. 예측이 어느 한 부분에서 좀 잘못된게 있지만 나머지 부분에서는 잘 돈것을 확인할 수 있다.
그래프의 y값에 실제 종가를 x값에 시간으로 표현하여 나타내어 확인을 해볼 필요가 있어 보인다. 또한 그래서 다음 날의 예측 종가가 얼마인지 확인하여 실제 종가랑 비교하여 나타낼 방안이 필요해 보인다.
또한, 데이터값이 총 200개로 적은 느낌이 있다. 더 많은 데이터로 훈련하고 테스트 데이터를 늘려서 진행을 해보고 다른 값을 이용해 볼 필요가 있다.
Reference
https://blog.naver.com/tkdlqm2/221575377059
https://colab.research.google.com/github/Hvass-Labs/TensorFlow-Tutorials/blob/master/23_Time-Series-Prediction.ipynb
'python' 카테고리의 다른 글
| [python] Pycharm Git / worktree (0) | 2021.06.30 |
|---|---|
| [Python]Pycharm 플러그인 (0) | 2021.06.29 |
| [Python] Pandas 데이터 프레임 (엑셀, 크롤링) (1) | 2020.06.14 |
| XSD: XML 스키마 정의 (0) | 2020.05.13 |
| [python] XML 파일 만들기 (0) | 2020.05.08 |