의사결정트리란 트리를 내려가면서 질문을 하고 그 질문의 응답에 따라 어떤 분류에 속하는지를 결정하는 것이다. 분류결과를 사람이 쉽게 이해하기 위해 노드들을 가장 효율적으로 선정하고 배치하기 위해 정보 획득량과 엔트로피라는 개념이 필요하다.
다음과 같은 그림을 보자.
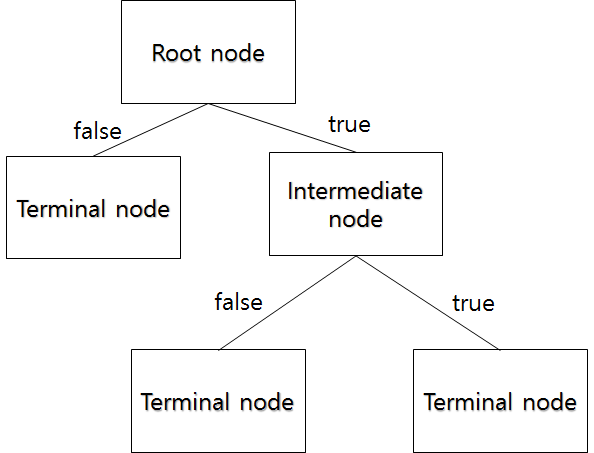
일반화 하면 이와 같다. 컴공이라면 이진 트리와 비슷한 느낌을 받을 수 있다. 시작 지점은 Root node이고 분기가 거듭될 수록 그에 해당하는 데이터의 수가 줄어들며 각 Terminal node에 속하는 데이터의 개수를 합하면 Root node의 데이터수와 일치한다.
이 의사결정트리는 분류와 회귀 모두 가능하다. 범주나 연속형 수치 모두 예측할 수 있다. 분류 과정은 새로운 데이터가 특정 Terminal node에 속한다는 정보를 확인한 뒤 해당 Terminal node에서 가장 빈도가 높은 범주에 새로운 데이터를 분류한다. 예를 들어 돈은 있는데 몸이 좋지 않으면 놀지 않는다 라고 예측합니다.
회긔는 Terminal node의 종속변수의 평균을 예측값으로 반환하는데 이 예측값의 종류는 Terminal node 개수와 일치한다.
의사결정트리는 구분 뒤 각 영역의 순도가 증가 혹은 불확실성이 최대한 감소하도록 하는 방향으로 학습을 진행한다. 여기서 정보획득량 이에 따라 엔트로피의 개념이 등장한다.
정보함수, 정보량
정보의 가치를 반환하는데 발생할 확률이 작은 사건일수록 정보의 가치가 크고 반대로 발생할 확률이 큰 사건일수록 정보의 가치가 작다.
예를 들어 확률이 1에 가까울수록 무조건 일어날수록 0에 수렴, ‘아침에 해가 뜬다’ 확률이 1에 가깝고 이를 통해 얻을 수 있는 정보는 없다.

엔트로피
엔트로피는 무질서도를 정량화해서 표현한 것, 어떤 집합의 엔트로피가 높을수록 그 집단의 특징을 찾는 것이 어렵다. 의사결정 트리에서 자식 노드들의 엔트로피가 최소가 되는 방향으로 분류분 나가는 것이 최적이다. 정보량의 평균을 의미한다.

예를 들어 스웨덴 vs 멕시코 전의 엔트로피도 계산하려고 한다. 스웨덴이 멕시코에게 이길 확률을 36%, 멕시코가 이길 확률을 34%, 비길 확률을 30%로 잡았다. 매우 박빙의 승부로 예측한 것이다. 그러면 스웨덴과 멕시코 경기의 엔트로피는 얼마일까?
0.36 * (-log0.36) + 0.34(-log0.34) + .... 은 1.5809 정도 나온다. 이 정보량이 클수록 결과가 예상이 되는 값이고 결과 예측이 힘들수록 엔트로피가 크다.
엔트로피가 감소한다는 것은 불확실성이 감소하고 순도가 증가하며 정보를 획득한 것이다. 의사결정트리는 구분 뒤 각 영역의 순도가 증가, 불확실성(엔트로피) 가 최대한 감소하도록 학습을 진행한다.
의사결정트리의 학습은 재귀적 분기와 가지치기 두가지가 있다.
재귀적 분기 : 어떤 데이터가 있을 때, 항목하나를 기준으로 정렬 -> 첫 번째 레코드와 나머지 레코드 간의 엔트로피를 구한 뒤 이를 분기 전 엔트로피와 비교해 정보획득을 조사함
가지치기 : Full tree(터미널 노드의 순도가 100%인 상태)를 생성한 뒤 적절한 수준에서 터미널 노드를 결합해야함. 그렇지 않으면 분기가 너무 많아서 학습데이터에 Overfitting우려. 결정트리의 분기수가 증가할 때 새 데이터에 대한 오분류율이 감소하나 일정 수준 이상 깊어지면 오분류율 증가, 이를 위해 가지치기를 수행, 가지치기는 분기를 Merge하는 개념.
-예제코드-
scikit-learn 에서 DecisionTreeClassifier에 구현되어 있다. 이것은 트리 생성을 일찍 중단하는 사전 가지치기만을 지원한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
import numpy as np
import pandas as pd
from pandas import DataFrame
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pydotplus
from IPython.display import Image
from sklearn.metrics import classification_report, confusion_matrix
#시각화를위해 graphviz 및 ipython 라이브러리 설치
wine = load_wine() # type: Bunch
#pandas DataFrame으로 데이터 넣음
wine_pd = pd.DataFrame(data=np.c_[wine['data'], wine['target']],
columns=wine['feature_names'] + ['target']) # type: DataFrame
#자동으로 데이터셋을 분리함
train_set, test_set = train_test_split(wine_pd, test_size=0.2, random_state=42)
##########################################
#결정트리는 DecisionTreeClassifier 클래스로 구현되어있다.
#위에서 분리한 데이터셋을 기반으로 트리를 학습
tree_clf = DecisionTreeClassifier(criterion='entropy', max_depth=5) # type: DecisionTreeClassifier
features = list(train_set.columns[:13])
#데이터 표준화 작업
X = train_set[features]
y = train_set['target']
X_test = test_set[features]
y_test = test_set['target']
y_pred = tree_clf.predict(X_test)
print(classification_report(y_test, y_pred))
##시각화 : graphviz를 사용
dot_data = export_graphviz(tree_clf, out_file=None, feature_names=features,
filled=True, rounded=True, special_characters=True)
# 그래프를 그림
graph = pydotplus.graph_from_dot_data(dot_data)
# 그린 그래프를 저장
graph.write_png("depth_5_giniHur.png")
#Image(graph.create_png())
http://colorscripter.com/info#e" target="_blank" style="color:#4f4f4ftext-decoration:none">Colored by Color Scripter
|

Reference
https://ratsgo.github.io/machine%20learning/2017/03/26/tree/
'NLP_자연언어처리, Colab' 카테고리의 다른 글
| [Colab] Histogram 코드 (0) | 2020.04.07 |
|---|---|
| [NLP] Word2Vec : CBOW, Skip-gram (0) | 2019.08.30 |
| [NLP]합성곱 신경망_CNN : CIFAR-10 (0) | 2019.08.05 |
| [NLP]MNIST 문자 인식 (0) | 2019.07.22 |
| [자연언어처리] 다층 퍼셉트론 (0) | 2019.07.09 |