Word2Vec
워드투백터 라는 개념이 나온다. 이 백터화 라는 개념이 나오기 전에 이전에는 'one-hot encoding' 방식을 사용했다. 이것은 쉽게 말해 단어 n개짜리 사전이 있다고 생각할 때, 길이 n짜리 벡터를 하나 만들고 그 단어가 해당되는 자리에 1을 넣고 나머지에는 0으로 채우는 방식이다.
예를들어 사전이 [서울, 부산, 대전, 인천] 이라면 서울은 [1, 0, 0, 0] 으로 표현이된다. 이 방식은 단어가 본질적으로 다른 단어와 어떤 차이점을 가지는지 이해할 수 없다는 단점이 있다.
이를 해결하기 위해, 단어 자체가 가지는 의미를 다차원 공간에서 '벡터화' 하는 방식이 나타났다. 단어들이 벡터공간에 흩어져있다고 생각하여 각 단어들 사이이 유사도를 측정할 수 있다는 것이다.
예를들어 '서울'에 대한 벡터에서 '강남'에 대한 벡터를 빼고, '해운대'에 대한 벡터를 넣는다면, 이 벡터연산은 새로운 벡터와 가장 가까운 단어인 '부산' 이라는 결과를 얻을 수 있을 것이다.
이 사이트에서 테스트할 수 있다. http://word2vec.kr/search/
그렇다면 어떻게 할 수 있는가?? 그것을 알아보기 위해 'CBOW' 모델과 'Skip-gram' 모델을 알아보고 코드를 통해 각 단어의 유사도를 측정해볼 것이다.
CBOW

CBOW 모델의 구조이다. 우선 결과만 말하면, 주어진 단어에 대해 앞뒤로 몇개의 단어를 Input으로 사용하여 주어진 단어를 유추하는 모델이다. 계산을 설명하자면Input Layer에서 hidden Layer로 갈 때는 모든 단어들이 공통적으로 사용하는 V x N 크기의 Hidden Matrix W가 있고 (N은 Hidden Layer의 길이 = 사용할 벡터의 길이),
Hidden Layer에서 Output Layer로 갈 때는 NxV 크기의 Weight Matrix W' 가 있다. Input에서는 단어를 one-hot encoding 으로 넣어주고, 여러 개의 단어를 각각 projection 시킨 후 그 벡터들의 평균을 구해서 hidden Layer 에 보낸다. 그 뒤는 여기에 Weight Matrix를 곱해서 Output Layer로 보내고 softmax 계산을 한 후, 이 결과를 진짜 단어의 one-hot encoding과 비교하여 에러를 계산한다.
Skip-gram
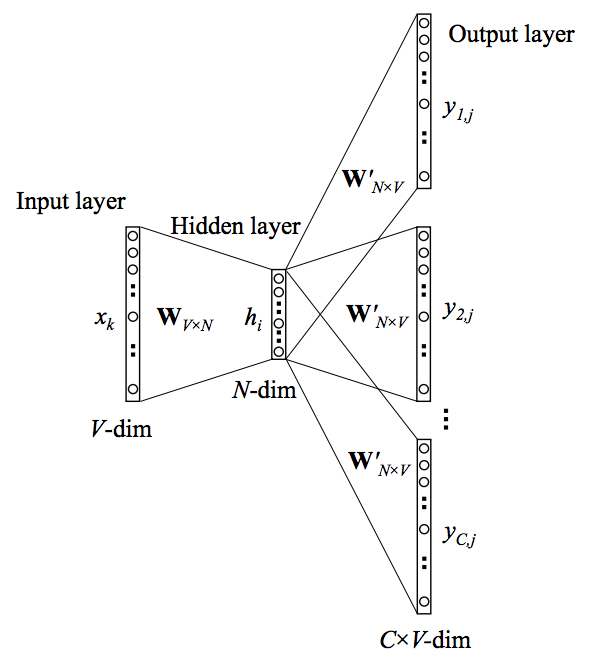
Skip-gram 모델의 구조이다. 결과만 말하면 CBOW와 반대의 개념이다. 현재 주어진 단어 하나를 가지고 주위에 등장하는 몇개의 단어들의 등장 여부를 유추하는 것이다. 이 때, 예측하는 단어들의 경우 현재 단어 주위에서 샘플링하는데 '가까이 위치해 있는 단어일 수록 현재 단어와 관련이 더 많을 것이다' 라는 생각을 적용한다.
간단한 예를 보면, 1 2 3 4 ... 이라는 숫자가 단어라고 생각하자. 윈도우의 크기는 2 즉 앞뒤로 2단어씩 본다.
1은 1을 기준으로 2, 3 단어를 보면서 1은 2를 넣고 학습을 시도하고 3을 넣어서 학습을 학습하게 된다.
2는 '1', '3', '4' 를 각각 주변단어 정답으로 두는 과정을 진행한다.
이렇게 모든 단어를 윈도우 크기로 이동해가며 학습을 진행한다.
이러한 방식이 CBOW보다 성능이 좋은 이유이다. 윈도우의 크기가 2이면 업데이트 기회를 4번이나 확보한다.
이 두모델에 대해 Output Layer에서 Softmax 연산을 하기위해 Normalization을 해주어야 하고 추가적인 연산을 이 부분에 투자하는데, 이 부분의 계산량을 줄이는 방법들이 있다.
Negative Sampling과 Hierarchical Softmax가 있다.
Konlpy
그럼 실습 코드를 보기전, 형태소분석을 위한 Konlpy에 대해서만 간단하고 보고가자.
Konlpy는 한국어 자연어처리를 할 수 있는 파이썬 패키지이다. 파이썬의 범언어적 자연어처리 패키지인 NLTK와 마찬가지로, 자연어처리를 이제 시작한 학생이나 연구 목적으로 사용하기 위한 연구자에게 적합한 패키지이다. 한국어 처리를 위한 용례검색, 혈태소 분석과 태깅, 최빈 형태소 찾기 등의 기능을 제공하며 다른 패키지와 함께 사용할 수 있는 장점을 가지고 있다.
관련 논문과 공식 홈페이지를 참조하자.
https://konlpy-ko.readthedocs.io/ko/v0.4.3/
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
import codecs
from bs4 import BeautifulSoup
#형태소 분석을 위해 knolpy를 설치
# 파일 열기
temp_file = "kor12.txt"
writeFp = open(temp_file, "w", encoding="utf-8")
#각 section의 텍스트 파일을 불러옴 1~9번까지 텍스트 데이터가 있음
#원본 문장을 읽어서 임의의 kor12파일을 생성, 이파일에서 어미 조사 구두점 등을 대상에서 제외할것임
# 형태소 분석
twitter = Okt()
i = 0
# 텍스트를 한 줄씩 처리하기
while True:
line = readFp.readline()
if not line: break
if i % 100 == 0:
print("current - " + str(i))
i += 1
# 형태소 분석
# 필요한 어구만 대상으로 하기
r = []
for word in malist:
# 어미/조사/구두점 등은 대상에서 제외
if not word[1] in ["Josa", "Eomi", "Punctuation"]:
writeFp.close()
data = word2vec.Text8Corpus("kor12.txt")
model = word2vec.Word2Vec(data, size = 100, window=5, min_count=2, iter=5000)
#size : word vector의 차원 , window크기 5, 최소 출현수 2, CBOW사용, 5000번 학습
#10000번 학습을 하면 시간이 너무 오래걸린다.
#print("ok")
#" 단어 "와의 유사도를 검색
print(res,sep="\n")
http://colorscripter.com/info#e" target="_blank" style="color:#4f4f4ftext-decoration:none">Colored by Color Scripter
|
Word2vec 의 패키지를 위해 gensim 패키지를 사용하였다. konlpy 패키지는 공식문서에 설치 방법과 사용법이 나와있다. 한글 텍스트를 기반으로 데이터를 사용하였으며 공개하지는 않겠다. 유사도 뿐아니라 정확도도 제공하는 메서드가 있다.
Word2Vec 메서드에서 모델을 정의할 수 있으며 상세한 내용은 공식 문서에 나와있다.
Reference
http://dsp.yonsei.ac.kr/progress/139926
https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/03/30/word2vec/
'NLP_자연언어처리, Colab' 카테고리의 다른 글
| [Colab]Canny Edge Detector_hough transform_Edge 탐색 코드 (0) | 2020.04.07 |
|---|---|
| [Colab] Histogram 코드 (0) | 2020.04.07 |
| [NLP]의사 결정 트리 (0) | 2019.08.25 |
| [NLP]합성곱 신경망_CNN : CIFAR-10 (0) | 2019.08.05 |
| [NLP]MNIST 문자 인식 (0) | 2019.07.22 |